From 7ca5abf9904dcffc30e40a93769fd573aded9c13 Mon Sep 17 00:00:00 2001
From: Edmond Yoo <hj3yoo@uwaterloo.ca>
Date: Sun, 14 Oct 2018 02:41:05 +0000
Subject: [PATCH] Wrapping up - adding files to make main program reproducible
---
/dev/null | 0
requirements.txt | 13 ++
card_pool.pck | 0
config.py | 2
transform_data.py | 24 ++--
opencv_dnn.py | 194 +++++++++++++++-----------------------
README.md | 46 ++++++++-
7 files changed, 144 insertions(+), 135 deletions(-)
diff --git a/README.md b/README.md
index 059a3c5..55a9a25 100644
--- a/README.md
+++ b/README.md
@@ -1,7 +1,33 @@
+# Magic: The Gathering Card Detector
-# Magic: The Gathering Card Detection Model
+MTG Card Detector is a real-time application that can identify Magic: The Gathering playing cards from either an image or a video. It utilizes various computer vision techniques to process the input image, and uses [perceptual hashing](https://jenssegers.com/61/perceptual-image-hashes) to identify the detected image of the cards with the matching cards from the database of MTG cards. Refer to [opencv_dnn.py](https://github.com/hj3yoo/mtg_card_detector/blob/master/opencv_dnn.py) for more detailed implementation.
-This is a fork of [Yolo-v3 and Yolo-v2 for Windows and Linux by AlexeyAB](https://github.com/AlexeyAB/darknet#how-to-compile-on-linux) for creating a custom model for [My MTG card detection project](https://github.com/hj3yoo/MTGCardDetector).
+**Demo:**
+
+[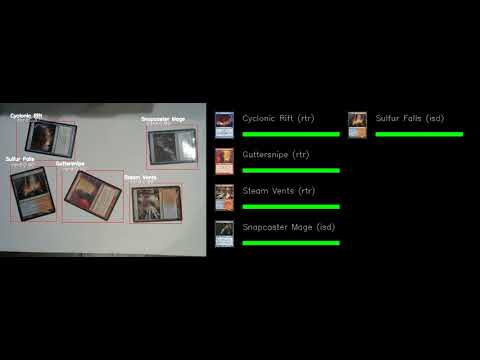](https://www.youtube.com/watch?v=BZkRZDyhMRE "Demo #1")
+
+You can run the demo using the following:
+
+```
+python3 opencv_dnn.py [-i path/to/input/file -o path/to/output/directory -hs (one of 16/32) -dsp -dbg -gph]
+```
+
+Initially, the project used a powerful neural network named ['You Only Look Once (YOLO)'](https://arxiv.org/pdf/1506.02640v5.pdf) to detect individual cards, but it has been removed as of Oct 12th, 2018 [(note)](https://github.com/hj3yoo/mtg_card_detector#oct-12th-2018) in favour of classical CV techniques.
+
+**Demo:**
+
+[](https://www.youtube.com/watch?v=kFE_k-mWo2A "Demo #2")
+
+You can still find the files used to train them:
+
+- [tiny_yolo.cfg](https://github.com/hj3yoo/mtg_card_detector/blob/master/cfg/tiny_yolo.cfg)
+- [tiny_yolo_final.weights](https://github.com/hj3yoo/mtg_card_detector/blob/master/weights/second_general/tiny_yolo_final.weights)
+- [obj.data](https://github.com/hj3yoo/mtg_card_detector/blob/master/data/obj.data) and [obj.names](https://github.com/hj3yoo/mtg_card_detector/blob/master/data/obj.names)
+- [fetch_data.py](https://github.com/hj3yoo/mtg_card_detector/blob/master/fetch_data.py): aggregates card images and database from [scryfall.com](https://scryfall.com/)
+- [transform_data.py](https://github.com/hj3yoo/mtg_card_detector/blob/master/transform_data.py): generate training images using the aggregated card images and database
+- [setup_train.py](https://github.com/hj3yoo/mtg_card_detector/blob/master/setup_train.py): create train.txt and test.txt required to train YOLO from the training dataset
+
+---------------------------------------------------------------------
## Day ~0: Sep 6th, 2018
@@ -120,13 +146,13 @@
## Oct 12th, 2018
-I've been able to significantly cut down the processing time of the current implementation. For n cards detected in the video, the latency has decreased from (65+50n)ms to (10+25n)ms. There were two major bottlenecks that was slowing the program down:
+I've been able to significantly cut down the processing time of the current implementation. For n cards detected in the video, the latency has decreased from (65+50n)ms to (7+16n)ms. There were two major bottlenecks that was slowing the program down:
--------------------------
In order to identify the card from the snippet of the card image, I'm using perceptual hashing. When the card is detected in YOLO, I compute its pHash value from its image, and compare it with the pHash of every cards in the database to find the match. This process has a speed of O(n * m), where n is the number of cards detected in the image and m is the number of cards in the database. With more than 10000 different cards printed in MTG history, this computation was the first bottleneck. For the 50ms increment per detected card mentioned above, majority of that time was spent trying to subtract two 1024-bit hashes 10000+ times - that's more than 10^10 comparisons right there!
-Although I couldn't cut down on the number of arithmetics, I did find another place that was unncessarily slowing things down. The following is the elapsed time for subtracting pHash for all 10000 elements in pandas database:
+First, there were some overhead that was coming from the implementation of the library. The following is the elapsed time for subtracting pHash for all 10000 elements in pandas database:
| hash_size | elapsed_time (ms) |
|---|---|
@@ -173,8 +199,18 @@
| 32 | 18.55 |
| 64 | 45.79 |
+Furthermore, turns out that hash size of 16 is sufficient enough to distinguish each cards in most of the case. Halving the hash size further knocked down 7-9ms, as you only need to compare about quarter of the bits compared to hash size of 32.
+
------------------
The other bottleneck is a something unfortunate. Turns out feeding the image through YOLO network consumes a constant 50 - 60ms per frame. Remember the processing time of (65+50)ms above? Yeah, that's where the 65ms is coming from.
-As hilarious and ironic it is, I would have to remove the network entirely to speed up the program... (((Facepalm into another dimension))) The program still works by replacing neural net with contour detection
\ No newline at end of file
+As hilarious and ironic it is, I would have to remove the network entirely to speed up the program...
+**(((Facepalm into another dimension)))**
+The program still works by replacing neural net with contour detection
+
+## Oct 13th, 2018
+
+Cleaning up everything to wrap up this project for now. If I can figure out how to move from bounding boxes of overlapping cards [(notes)](https://github.com/hj3yoo/mtg_card_detector#oct-4th-2018), I may come back to upgrade the project in the future. If you have any suggestion regarding this issue, please don't hesitate to let me know.
+
+Thank you for reading all the way up to here. Hope this project has helped you in some way.
\ No newline at end of file
diff --git a/anchors.txt b/anchors.txt
deleted file mode 100644
index e343990..0000000
--- a/anchors.txt
+++ /dev/null
@@ -1 +0,0 @@
-118.5833,137.6176, 95.9314,181.2641, 140.8155,166.6721, 113.2913,220.6833, 128.8767,197.7804, 158.9573,196.7482, 138.7983,242.8474, 167.2494,227.1953, 165.0362,253.8635
\ No newline at end of file
diff --git a/card_pool.pck b/card_pool.pck
new file mode 100644
index 0000000..e6c05be
--- /dev/null
+++ b/card_pool.pck
Binary files differ
diff --git a/card_pool_32_4.pck b/card_pool_32_4.pck
deleted file mode 100644
index dc9e1c0..0000000
--- a/card_pool_32_4.pck
+++ /dev/null
Binary files differ
diff --git a/config.py b/config.py
index 0e77db2..89a338b 100644
--- a/config.py
+++ b/config.py
@@ -20,7 +20,7 @@
'ddt', 'v17', 'ddu', 'cm2', 'ss1', 'gs1', 'c18']
# Supplemental sets
set_sup_list = ['hop', 'arc', 'pc2', 'cns', 'cn2', 'e01', 'e02', 'bbd']
- all_set_list = set_2003_list #+ set_2015_list + set_box_list + set_sup_list
+ all_set_list = set_2003_list + set_2015_list + set_box_list + set_sup_list
card_mask_path = os.path.abspath('data/mask.png')
data_dir = os.path.abspath('/media/win10/data')
diff --git a/opencv_dnn.py b/opencv_dnn.py
index 9f83caa..7801bc3 100644
--- a/opencv_dnn.py
+++ b/opencv_dnn.py
@@ -1,3 +1,4 @@
+import argparse
import ast
import collections
import cv2
@@ -22,19 +23,24 @@
"""
-def calc_image_hashes(card_pool, save_to=None, hash_size=32, highfreq_factor=4):
+def calc_image_hashes(card_pool, save_to=None, hash_size=None):
"""
Calculate perceptual hash (pHash) value for each cards in the database, then store them if needed
:param card_pool: pandas dataframe containing all card information
:param save_to: path for the pickle file to be saved
:param hash_size: param for pHash algorithm
- :param highfreq_factor: param for pHash algorithm
:return: pandas dataframe
"""
+ if hash_size is None:
+ hash_size = [16, 32]
+ elif isinstance(hash_size, int):
+ hash_size = [hash_size]
+
# Since some double-faced cards may result in two different cards, create a new dataframe to store the result
new_pool = pd.DataFrame(columns=list(card_pool.columns.values))
- new_pool['card_hash'] = np.NaN
- #new_pool['art_hash'] = np.NaN
+ for hs in hash_size:
+ new_pool['card_hash_%d' % hs] = np.NaN
+ #new_pool['art_hash_%d' % hs] = np.NaN
for ind, card_info in card_pool.iterrows():
if ind % 100 == 0:
print('Calculating hashes: %dth card' % ind)
@@ -68,20 +74,15 @@
print('WARNING: card %s is not found!' % img_name)
# Compute value of the card's perceptual hash, then store it to the database
- '''
- img_art = Image.fromarray(card_img[121:580, 63:685]) # For 745*1040 size card image
- art_hash = ih.phash(img_art, hash_size=hash_size, highfreq_factor=highfreq_factor)
- card_info['art_hash'] = art_hash
- '''
+ #img_art = Image.fromarray(card_img[121:580, 63:685]) # For 745*1040 size card image
img_card = Image.fromarray(card_img)
- card_hash = ih.phash(img_card, hash_size=hash_size, highfreq_factor=highfreq_factor)
- card_info['card_hash'] = card_hash
+ for hs in hash_size:
+ card_hash = ih.phash(img_card, hash_size=hs)
+ card_info['card_hash_%d' % hs] = card_hash
+ #art_hash = ih.phash(img_art, hash_size=hs)
+ #card_info['art_hash_%d' % hs] = art_hash
new_pool.loc[0 if new_pool.empty else new_pool.index.max() + 1] = card_info
- # Remove uselesss fields, then pickle it if needed
- new_pool = new_pool[['artist', 'border_color', 'collector_number', 'color_identity', 'colors', 'flavor_text',
- 'image_uris', 'mana_cost', 'legalities', 'name', 'oracle_text', 'rarity', 'type_line',
- 'set', 'set_name', 'power', 'toughness', 'art_hash', 'card_hash']]
if save_to is not None:
new_pool.to_pickle(save_to)
return new_pool
@@ -166,72 +167,6 @@
return warped
-'''
-# The following functions are only used in conjunction with YOLO, and is deprecated:
-# - get_outputs_names()
-# - post_process()
-# - draw_pred()
-# Get the names of the output layers
-def get_outputs_names(net):
- # Get the names of all the layers in the network
- layers_names = net.getLayerNames()
- # Get the names of the output layers, i.e. the layers with unconnected outputs
- return [layers_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
-
-
-# Remove the bounding boxes with low confidence using non-maxima suppression
-# https://www.learnopencv.com/deep-learning-based-object-detection-using-yolov3-with-opencv-python-c/
-def post_process(frame, outs, thresh_conf, thresh_nms):
- frame_height = frame.shape[0]
- frame_width = frame.shape[1]
-
- # Scan through all the bounding boxes output from the network and keep only the
- # ones with high confidence scores. Assign the box's class label as the class with the highest score.
- class_ids = []
- confidences = []
- boxes = []
- for out in outs:
- for detection in out:
- scores = detection[5:]
- class_id = np.argmax(scores)
- confidence = scores[class_id]
- if confidence > thresh_conf:
- center_x = int(detection[0] * frame_width)
- center_y = int(detection[1] * frame_height)
- width = int(detection[2] * frame_width)
- height = int(detection[3] * frame_height)
- left = int(center_x - width / 2)
- top = int(center_y - height / 2)
- class_ids.append(class_id)
- confidences.append(float(confidence))
- boxes.append([left, top, width, height])
-
- # Perform non maximum suppression to eliminate redundant overlapping boxes with lower confidences.
- indices = [ind[0] for ind in cv2.dnn.NMSBoxes(boxes, confidences, thresh_conf, thresh_nms)]
-
- ret = [[class_ids[i], confidences[i], boxes[i]] for i in indices]
- return ret
-
-
-# Draw the predicted bounding box
-def draw_pred(frame, class_id, classes, conf, left, top, right, bottom):
- # Draw a bounding box.
- cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255))
-
- label = '%.2f' % conf
-
- # Get the label for the class name and its confidence
- if classes:
- assert (class_id < len(classes))
- label = '%s:%s' % (classes[class_id], label)
-
- # Display the label at the top of the bounding box
- label_size, base_line = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
- top = max(top, label_size[1])
- cv2.putText(frame, label, (left, top), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
-'''
-
-
def remove_glare(img):
"""
Reduce the effect of glaring in the image
@@ -350,7 +285,9 @@
if os.path.exists(img_name):
card_img = cv2.imread(img_name)
else:
- card_img = np.ones((h_card, w_card))
+ card_img = np.ones((h_card, w_card, 3)) * 255
+ cv2.putText(card_img, 'X', ((w_card - int(txt_scale * 25)) // 2, (h_card + int(txt_scale * 25)) // 2),
+ cv2.FONT_HERSHEY_SIMPLEX, txt_scale, (0, 0, 0), 2)
# Insert the card image, card name, and confidence bar to the graph
img_graph[y_anchor:y_anchor + h_card, x_anchor:x_anchor + w_card] = card_img
@@ -369,14 +306,13 @@
return img_graph
-def detect_frame(img, card_pool, hash_size=32, highfreq_factor=4, size_thresh=10000,
+def detect_frame(img, card_pool, hash_size=32, size_thresh=10000,
out_path=None, display=True, debug=False):
"""
Identify all cards in the input frame, display or save the frame if needed
:param img: input frame
:param card_pool: pandas dataframe of all card's information
:param hash_size: param for pHash algorithm
- :param highfreq_factor: param for pHash algorithm
:param size_thresh: threshold for size (in pixel) of the contour to be a candidate
:param out_path: path to save the result
:param display: flag for displaying the result
@@ -402,13 +338,14 @@
'''
img_art = img_warp[47:249, 22:294]
img_art = Image.fromarray(img_art.astype('uint8'), 'RGB')
- art_hash = ih.phash(img_art, hash_size=hash_size, highfreq_factor=highfreq_factor).hash.flatten()
+ art_hash = ih.phash(img_art, hash_size=hash_size).hash.flatten()
card_pool['hash_diff'] = card_pool['art_hash'].apply(lambda x: np.count_nonzero(x != art_hash))
'''
img_card = Image.fromarray(img_warp.astype('uint8'), 'RGB')
# the stored values of hashes in the dataframe is pre-emptively flattened already to minimize computation time
- card_hash = ih.phash(img_card, hash_size=hash_size, highfreq_factor=highfreq_factor).hash.flatten()
- card_pool['hash_diff'] = card_pool['card_hash'].apply(lambda x: np.count_nonzero(x != card_hash))
+ card_hash = ih.phash(img_card, hash_size=hash_size).hash.flatten()
+ card_pool['hash_diff'] = card_pool['card_hash_%d' % hash_size]
+ card_pool['hash_diff'] = card_pool['hash_diff'].apply(lambda x: np.count_nonzero(x != card_hash))
min_card = card_pool[card_pool['hash_diff'] == min(card_pool['hash_diff'])].iloc[0]
card_name = min_card['name']
card_set = min_card['set']
@@ -417,11 +354,12 @@
# Render the result, and display them if needed
cv2.drawContours(img_result, [cnt], -1, (0, 255, 0), 2)
- cv2.putText(img_result, card_name, (pts[0][0], pts[0][1]), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
+ cv2.putText(img_result, card_name, (min(pts[0][0], pts[1][0]), min(pts[0][1], pts[1][1])),
+ cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
if debug:
# cv2.rectangle(img_warp, (22, 47), (294, 249), (0, 255, 0), 2)
- cv2.putText(img_warp, card_name + ', ' + str(hash_diff), (0, 50),
- cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
+ cv2.putText(img_warp, card_name + ', ' + str(hash_diff), (0, 20),
+ cv2.FONT_HERSHEY_SIMPLEX, 0.4, (255, 255, 255), 1)
cv2.imshow('card#%d' % i, img_warp)
if display:
cv2.imshow('Result', img_result)
@@ -432,14 +370,13 @@
return det_cards, img_result
-def detect_video(capture, card_pool, hash_size=32, highfreq_factor=4, size_thresh=10000,
+def detect_video(capture, card_pool, hash_size=32, size_thresh=10000,
out_path=None, display=True, show_graph=True, debug=False):
"""
Identify all cards in the continuous video stream, display or save the result if needed
:param capture: input video stream
:param card_pool: pandas dataframe of all card's information
:param hash_size: param for pHash algorithm
- :param highfreq_factor: param for pHash algorithm
:param size_thresh: threshold for size (in pixel) of the contour to be a candidate
:param out_path: path to save the result
:param display: flag for displaying the result
@@ -471,8 +408,8 @@
cv2.waitKey(0)
break
# Detect all cards from the current frame
- det_cards, img_result = detect_frame(frame, card_pool, hash_size=hash_size, highfreq_factor=highfreq_factor,
- size_thresh=size_thresh, out_path=None, display=False, debug=debug)
+ det_cards, img_result = detect_frame(frame, card_pool, hash_size=hash_size, size_thresh=size_thresh,
+ out_path=None, display=False, debug=debug)
if show_graph:
# If the card was already detected in the previous frame, append 1 to the list
# If the card previously detected was not found in this trame, append 0 to the list
@@ -528,18 +465,14 @@
cv2.destroyAllWindows()
-def main():
+def main(args):
# Specify paths for all necessary files
- #test_path = os.path.abspath('test_file/test4.mp4')
- test_path = None
- out_dir = 'out'
- hash_size = 32
- highfreq_factor = 4
- pck_path = os.path.abspath('card_pool_%d_%d.pck' % (hash_size, highfreq_factor))
+ pck_path = os.path.abspath('card_pool.pck')
if os.path.isfile(pck_path):
card_pool = pd.read_pickle(pck_path)
else:
+ print('Warning: pickle for card database %s is not found!' % pck_path)
# Merge database for all cards, then calculate pHash values of each, store them
df_list = []
for set_name in Config.all_set_list:
@@ -549,44 +482,67 @@
card_pool = pd.concat(df_list, sort=True)
card_pool.reset_index(drop=True, inplace=True)
card_pool.drop('Unnamed: 0', axis=1, inplace=True, errors='ignore')
+ calc_image_hashes(card_pool, save_to=pck_path)
+ ch_key = 'card_hash_%d' % args.hash_size
+ card_pool = card_pool[['name', 'set', 'collector_number', ch_key]]
- card_pool = calc_image_hashes(card_pool, save_to=pck_path, hash_size=hash_size, highfreq_factor=highfreq_factor)
- card_pool = card_pool[['name', 'set', 'collector_number', 'card_hash']]
+ # Processing time is almost linear to the size of the database
+ # Program can be much faster if the search scope for the card can be reduced
+ card_pool = card_pool[card_pool['set'].isin(Config.set_2003_list)]
# ImageHash is basically just one numpy.ndarray with (hash_size)^2 number of bits. pre-emptively flattening it
# significantly increases speed for subtracting hashes in the future.
- card_pool['card_hash'] = card_pool['card_hash'].apply(lambda x: x.hash.flatten())
-
+ card_pool[ch_key] = card_pool[ch_key].apply(lambda x: x.hash.flatten())
# If the test file isn't given, use webcam to capture video
- if test_path is None:
+ if args.in_path is None:
capture = cv2.VideoCapture(0)
- detect_video(capture, card_pool, out_path='%s/result.avi' % out_dir, display=True, show_graph=True, debug=False)
+ detect_video(capture, card_pool, hash_size=args.hash_size, out_path='%s/result.avi' % args.out_path,
+ display=args.display, show_graph=args.show_graph, debug=args.debug)
capture.release()
else:
- # Save the detection result if out_dir is provided
- if out_dir is None or out_dir == '':
+ # Save the detection result if args.out_path is provided
+ if args.out_path is None:
out_path = None
else:
- f_name = os.path.split(test_path)[1]
- out_path = '%s/%s.avi' % (out_dir, f_name[:f_name.find('.')])
+ f_name = os.path.split(args.in_path)[1]
+ out_path = '%s/%s.avi' % (args.out_path, f_name[:f_name.find('.')])
- if not os.path.isfile(test_path):
- print('The test file %s doesn\'t exist!' % os.path.abspath(test_path))
+ if not os.path.isfile(args.in_path):
+ print('The test file %s doesn\'t exist!' % os.path.abspath(args.in_path))
return
# Check if test file is image or video
- test_ext = test_path[test_path.find('.') + 1:]
+ test_ext = args.in_path[args.in_path.find('.') + 1:]
if test_ext in ['jpg', 'jpeg', 'bmp', 'png', 'tiff']:
# Test file is an image
- img = cv2.imread(test_path)
- detect_frame(img, card_pool, out_path=out_path)
+ img = cv2.imread(args.in_path)
+ detect_frame(img, card_pool, hash_size=args.hash_size, out_path=out_path, display=args.display,
+ debug=args.debug)
else:
# Test file is a video
- capture = cv2.VideoCapture(test_path)
- detect_video(capture, card_pool, out_path=out_path, display=True, show_graph=True, debug=False)
+ capture = cv2.VideoCapture(args.in_path)
+ detect_video(capture, card_pool, hash_size=args.hash_size, out_path=out_path, display=args.display,
+ show_graph=args.show_graph, debug=args.debug)
capture.release()
pass
if __name__ == '__main__':
- main()
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-i', '--in', dest='in_path', help='Path of the input file. For webcam, leave it blank',
+ type=str)
+ parser.add_argument('-o', '--out', dest='out_path', help='Path of the output directory to save the result',
+ type=str)
+ parser.add_argument('-hs', '--hash_size', dest='hash_size',
+ help='Size of the hash for pHash algorithm', type=int, default=16)
+ parser.add_argument('-dsp', '--display', dest='display', help='Display the result', action='store_true',
+ default=False)
+ parser.add_argument('-dbg', '--debug', dest='debug', help='Enable debug mode', action='store_true', default=False)
+ parser.add_argument('-gph', '--show_graph', dest='show_graph', help='Display the graph for video output',
+ action='store_true', default=False)
+ args = parser.parse_args()
+ if not args.display and args.out_path is None:
+ # Then why the heck are you running this thing in the first place?
+ print('The program isn\'t displaying nor saving any output file. Please change the setting and try again.')
+ exit()
+ main(args)
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000..0beb8e2
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,13 @@
+ast
+cv2==3.4.2
+imgaug==0.2.6
+imutils==0.5.1
+json==2.0.9
+matplotlib==2.2.2
+numpy==1.15.2
+pandas==0.23.0
+pickle
+PIL==5.1.0
+shapely==1.6.4
+urllib
+
diff --git a/transform_data.py b/transform_data.py
index 8e681a7..f4fa1a9 100644
--- a/transform_data.py
+++ b/transform_data.py
@@ -1,3 +1,4 @@
+import argparse
import cv2
import imgaug as ia
from imgaug import augmenters as iaa
@@ -489,7 +490,7 @@
self.visible = False
-def main():
+def main(args):
random.seed()
ia.seed(random.randrange(10000))
@@ -506,17 +507,12 @@
for i in range(len(class_name_list)):
class_ids[class_name_list[i]] = i
- num_gen = 60000
- num_iter = 1
- w_gen = 1440
- h_gen = 960
-
- for i in range(num_gen):
+ for i in range(args.num_gen):
# Arbitrarily select top left and right corners for perspective transformation
# Since the training image are generated with random rotation, don't need to skew all four sides
skew = [[random.uniform(0, 0.25), 0], [0, 1], [1, 1],
[random.uniform(0.75, 1), 0]]
- generator = ImageGenerator(background.get_random(), class_ids, w_gen, h_gen, skew=skew)
+ generator = ImageGenerator(background.get_random(), class_ids, args.width, args.height, skew=skew)
out_name = ''
# Use 2 to 5 cards per generator
@@ -536,7 +532,7 @@
card = Card(card_img, card_info, detected_object_list)
generator.add_card(card)
- for j in range(num_iter):
+ for j in range(args.num_iter):
seq = iaa.Sequential([
iaa.Multiply((0.8, 1.2)), # darken / brighten the whole image
iaa.SimplexNoiseAlpha(first=iaa.Add(random.randrange(64)), per_channel=0.1, size_px_max=[3, 6],
@@ -566,4 +562,12 @@
if __name__ == '__main__':
- main()
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-n', '--num_gen', dest='num_gen', help='Number of training images to generate',
+ type=int, required=True)
+ parser.add_argument('-ni', '--num_iter', dest='num_iter', help='Number of iterations to generate each config',
+ type=int, default=1)
+ parser.add_argument('-w', '--width', dest='width', help='Width of the training image', type=int, default=1440)
+ parser.add_argument('-ht', '--height', dest='height', help='Height of the training image', type=int, default=960)
+ args = parser.parse_args()
+ main(args)
--
Gitblit v1.10.0